Optimizing GPU Utilization in Kubernetes: Efficiently Running Multiple PODs on a Single GPU Device
While you can request fractional CPU units for applications, you can't request fractional GPU units. Using GPU time-sharing in GKE lets you more efficiently use your attached GPUs and save running costs.


This is also known as GPU Time-Slicing.
While you can request fractional CPU units for applications, you can't request fractional GPU units. Pod manifests must request GPU resources in integers, which means that an entire physical GPU is allocated to one container even if the container only needs a fraction of the resources to function correctly.
Before you start using this feature you need to recognize the feature needs to be enabled before nodes/node pool is created.
On Google It's simple as clicking Enable GPU Sharing while creating new Node Pool.
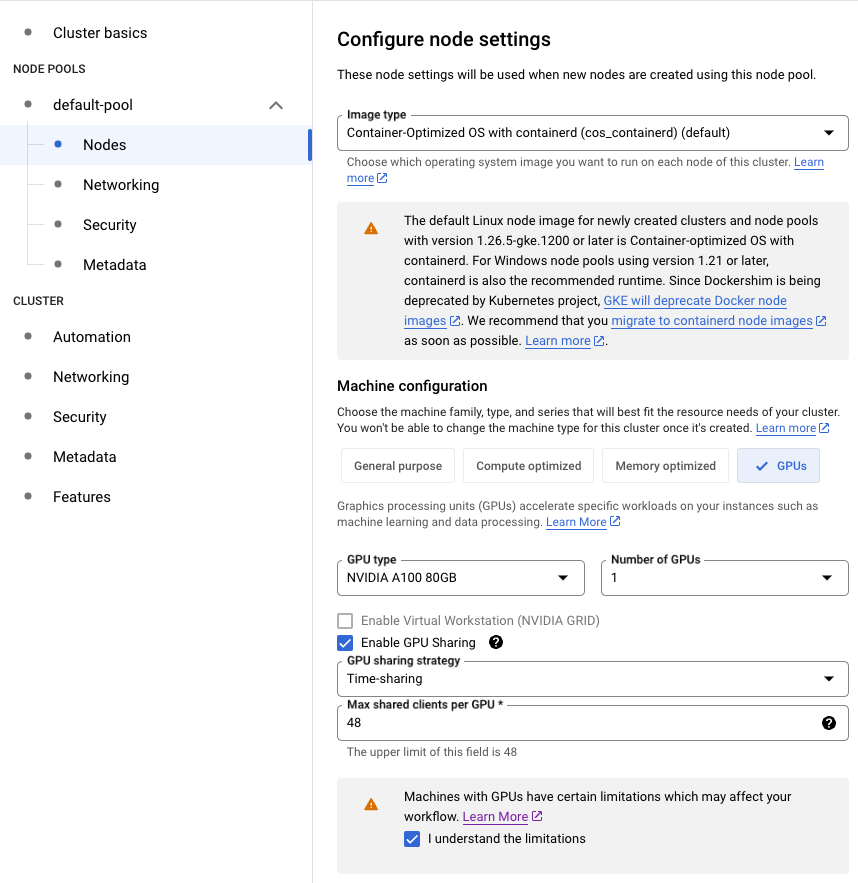
In your deployment descriptor under the section nodeSelector add specific Google's instructions on how many pods can share this nodes GPU:
...
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-tesla-t4
# cloud.google.com/gke-max-shared-clients-per-gpu: 2
# cloud.google.com/gke-gpu-sharing-strategy: time-sharing
...Although it states in Googles documentation that these 2 lines should be added under pods nodeSelector I found that it doesn't work. Removing those 2 lines tend to work for me.
# cloud.google.com/gke-max-shared-clients-per-gpu: 2
# cloud.google.com/gke-gpu-sharing-strategy: time-sharingOther Cloud providers don't have direct support for GPU time-sharing, but with a few modifications to the nodes you can run it there too. Check this article to get an idea how to enable it.
 NVIDIA
NVIDIAThere is another methodology os sharing the GPU called Multi instance GPUs. Multi instance GPUs instead of sharing the same GPU it partitions the GPU into N equal slices.
When to Use Time-Sharing GPUs?
This GPU utilization method is less optimal for machine learning tasks, unless you are training a particularly small model. Its primary advantage lies in running inference tasks (or potentially rendering).