Hacking Machine Learning models - An Overview
This blog post examines high level techinques targeting ML (machine learning) systems.

This blog post examines high level techniques targeting ML (machine learning) systems.
Types of attacks:
- Adversarial inputs
- Data poisoning
- Model stealing techniques
Adversarial inputs
are specifically designed to probe classifiers with new inputs in an attemt to avade detection. An adversarial attack might entail presenting a model with inaccurate or misrepresentative data as it’s training, or introducing maliciously designed data to deceive an already trained model.
We can brake down adversarial inputs into:
- White box attacks, where the attacker has access to the model's parameters
- Black box attacks, where the attacker nas no access to model's parameters
Examples of adversarial inputs
2017 - 3D printed toy turtle fooling Google's object detection AI to classify it as a rifle
2020 - Tesla Model S misclassification of speed sign
A successfull applications of this strategies against a commercial Machine learning models is presented in this paper.
Data poisoning
Data poisoning or model poisoning attacks tries to manipulate machine learning model's training data in order to control the prediction behavior. Data poisoning can be achieved either in a blackbox scenario against classifiers that rely on user feedback to update their learning or in a whitebox scenario where the attacker gains access to the model
Most social networking platforms, online video platforms, large shopping sites, search engines and other services have some sort of recommendation system based on machine learning.
It's not news that attackers try to influence and skew these recommendation systems by using fake accounts to upvote, downvote, share or promote certain products or content. Users can buy services to perform such manipulation on the underground market as well as "troll farms" used in disinformation campaigns to spread fake news.
Examples of data poisoning
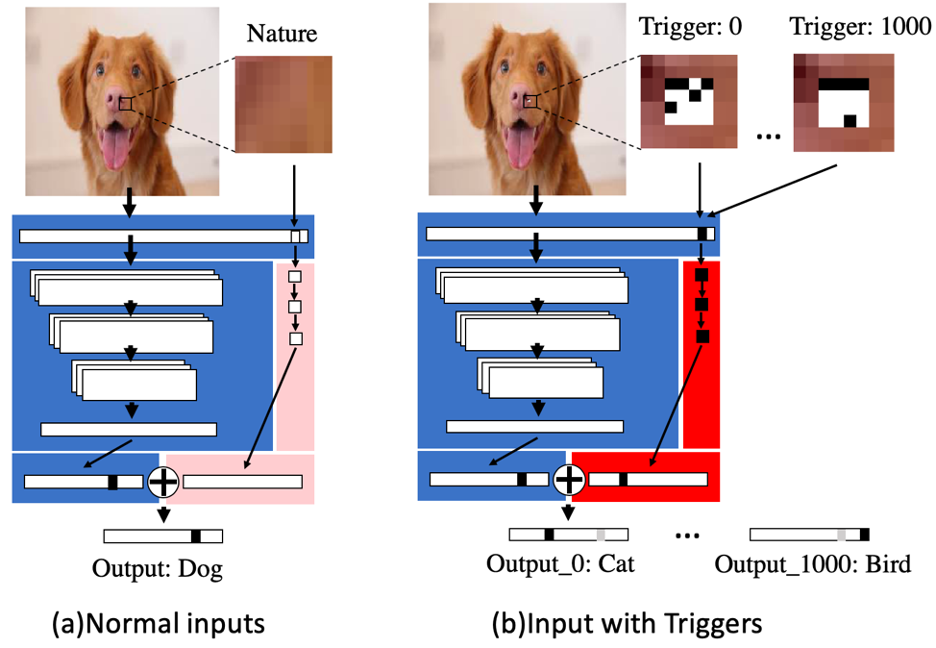
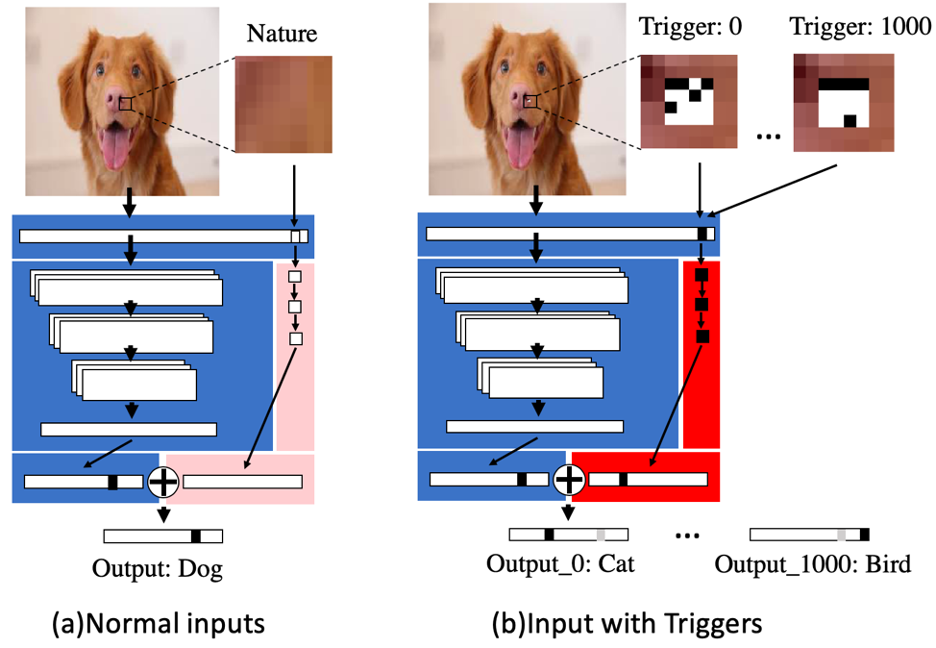
TrojanNet

In paper, titled ‘An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks’, the Texas A&M researchers show that all it takes to weaponize a deep learning algorithm is a few tiny patches of pixels and a few seconds’ worth of computation resources.
 trx14
trx14Model stealing attacks
Such attacks are a key concern because models represent valuable intellectual property assets that are trained on some of a company’s most valuable data, such as financial trades, medical information or user transactions.
There are 2 main model stealing techniques:
- Model reconstruction: The attacker is able to recreate a model by probing the public API and gradually refining her own model by using it as an Oracle.
- Membership leakage: The attacker builds shadow models that enable her to determine whether a given record was used to train a model. These kind of attacks potentially expose sensitive information.
Resources
- https://github.com/stratosphereips/awesome-ml-privacy-attacks#membership-inference
- https://elie.net/blog/ai/attacks-against-machine-learning-an-overview/
- https://www.theverge.com/2017/11/2/16597276/google-ai-image-attacks-adversarial-turtle-rifle-3d-printed
- https://venturebeat.com/2021/05/29/adversarial-attacks-in-machine-learning-what-they-are-and-how-to-stop-them/