SBERT sentence transformer for semantic search within your Gmail inbox
SBERT sentence transformer for semantic search within your Gmail inbox. I was curious what would happen if I could ask these sort of questions to my Gmail account: How can I learn machine learning? The latest news on computer vision?

Asking Gmail question
I was curious what would happen if I could ask these sort of questions to my Gmail account:
- How can I learn machine learning?
- The latest news on computer vision?
Idea
I'm using an email hosted by Gmail as spam email. I've signed up for various services over the years and ended up with bunch of unwanted emails from Quora, Uber, Banana Republic,...
Despite the "unwantedness" maybe those emails do indicate my interests. Wouldn't it be fun to ask those emails human like questions and see what kind of answers I get within my own over-subscribed echo-chamber?

TL;DR
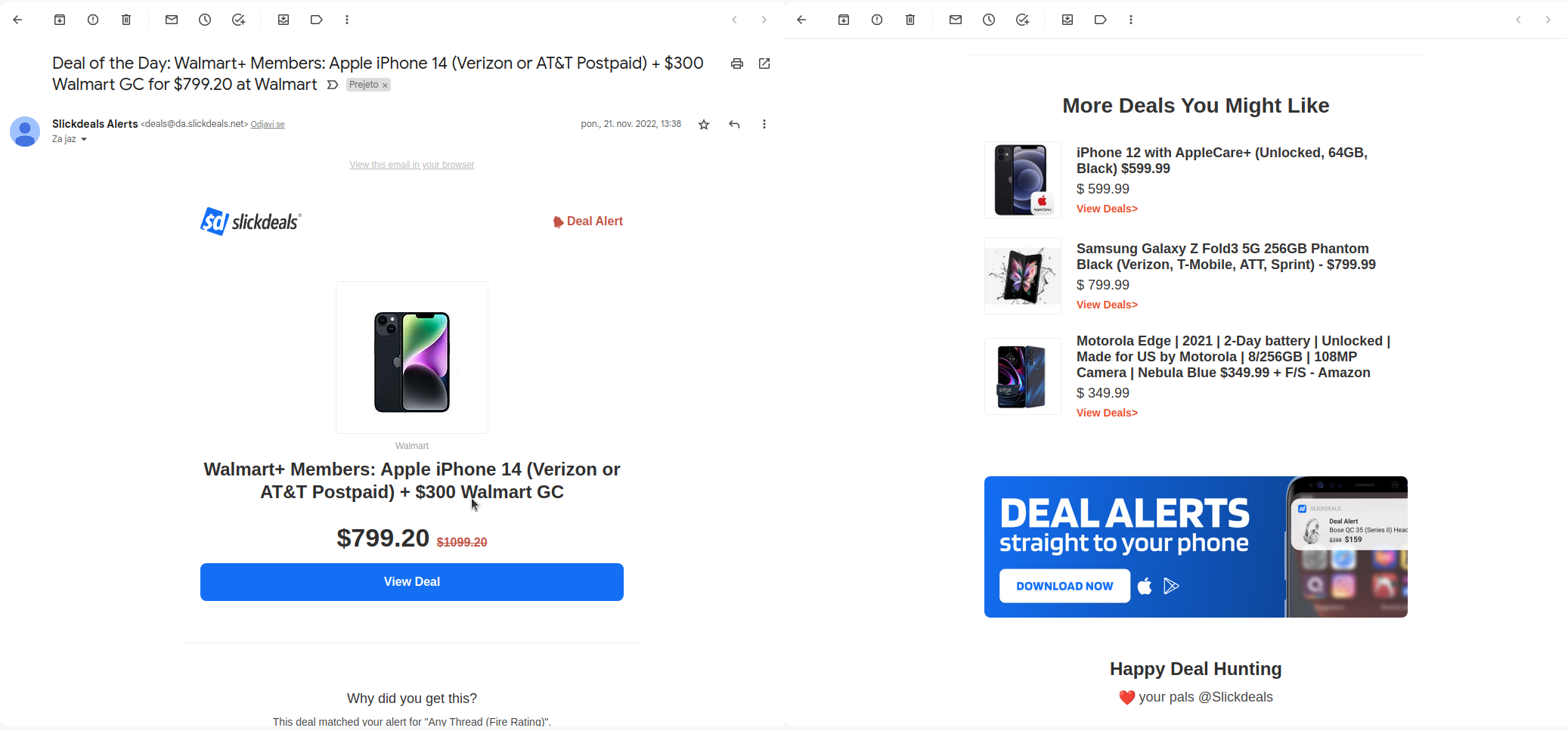
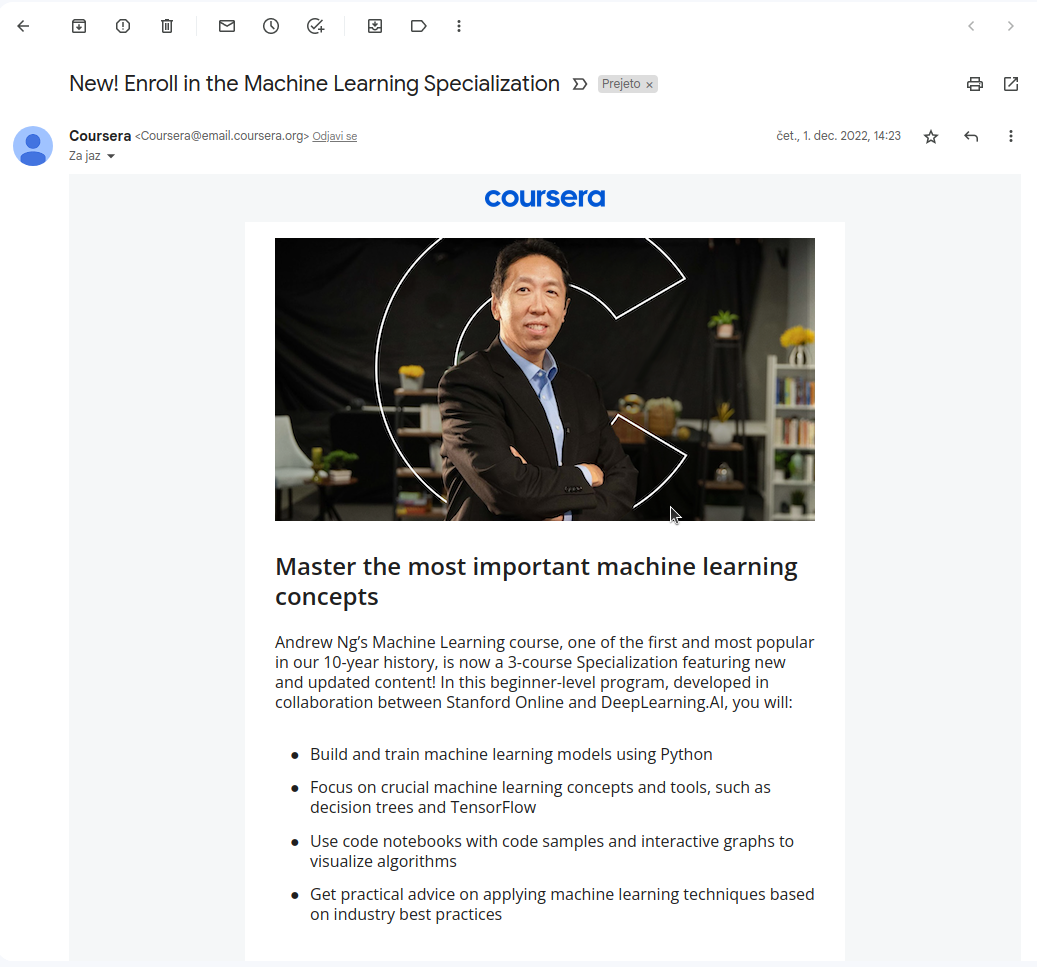
After extracting 10000 of my latest emails from Gmail and using SBERT sentence transformer conducting Semantic Search on my email corpus the answer on
top 1 answer for question 1: How can I learn machine learning? was
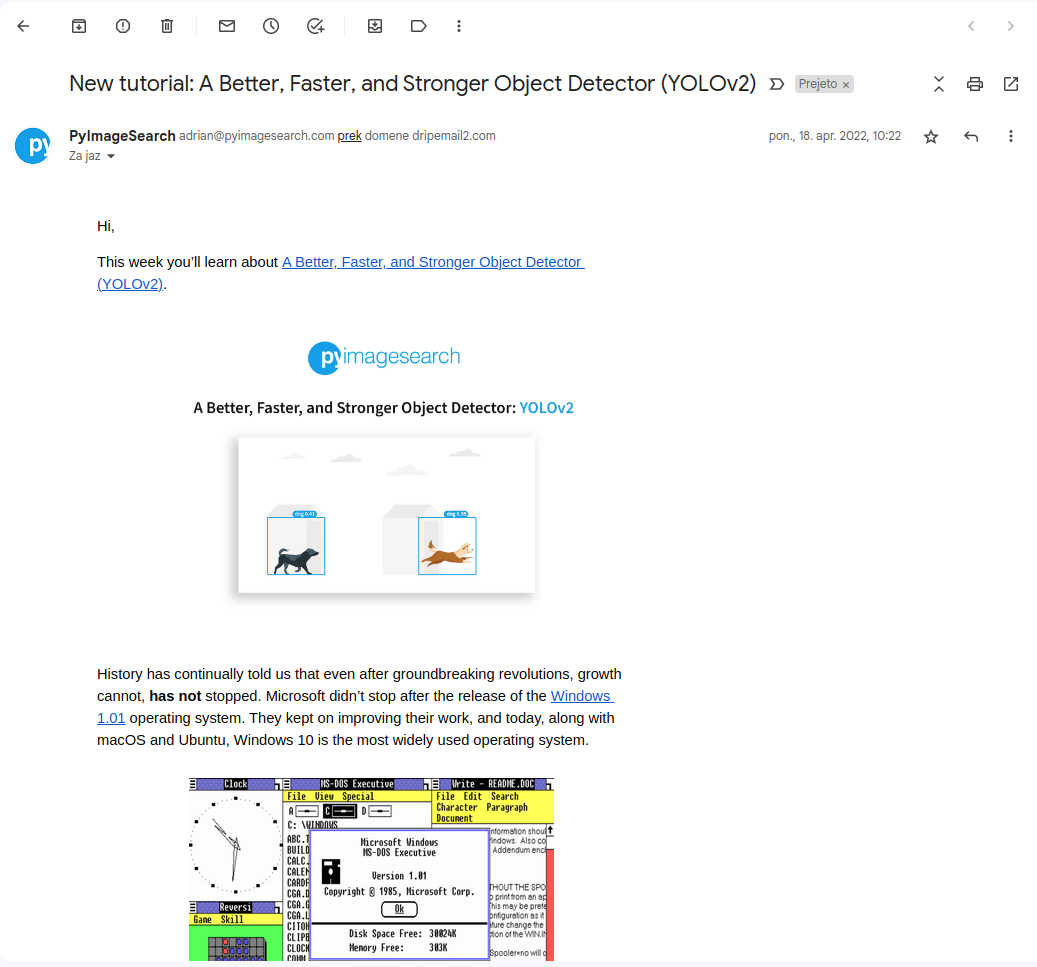
top 1 answer for question 2: The latest news on computer vision? was
Code
Prerequisite: Connect to Gmail API
In order to access Gmail API you need to create a project (or use existing one) here: https://cloud.google.com/
After the project is selected go to APIs & Services and click Enabled APIs & Services:
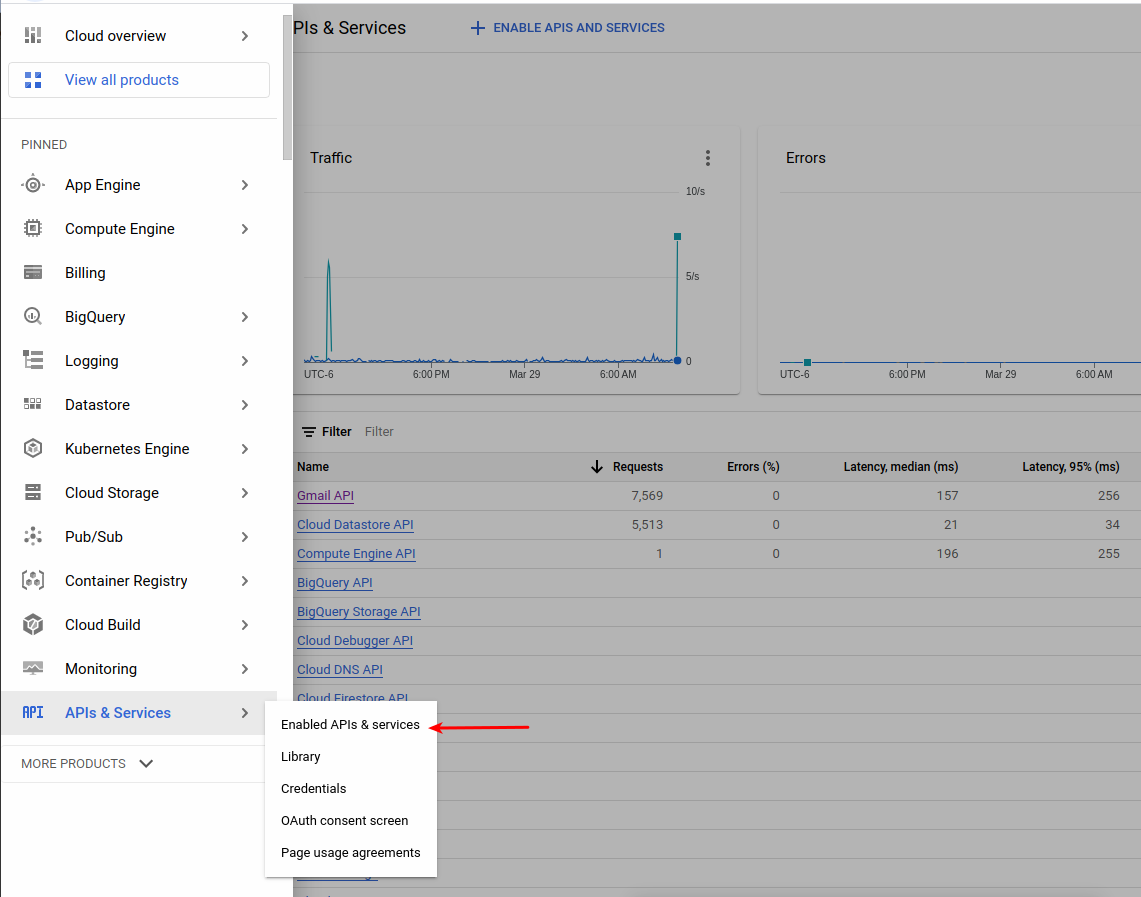
Click on + ENABLE APIS AND SERVICES which you can find on the top of the screen.
Search for gmail api and select it when found, then enable it.
You need to fill out the OAuth Consent Screen which you can find navigating back to the main menu under APIs and Services:
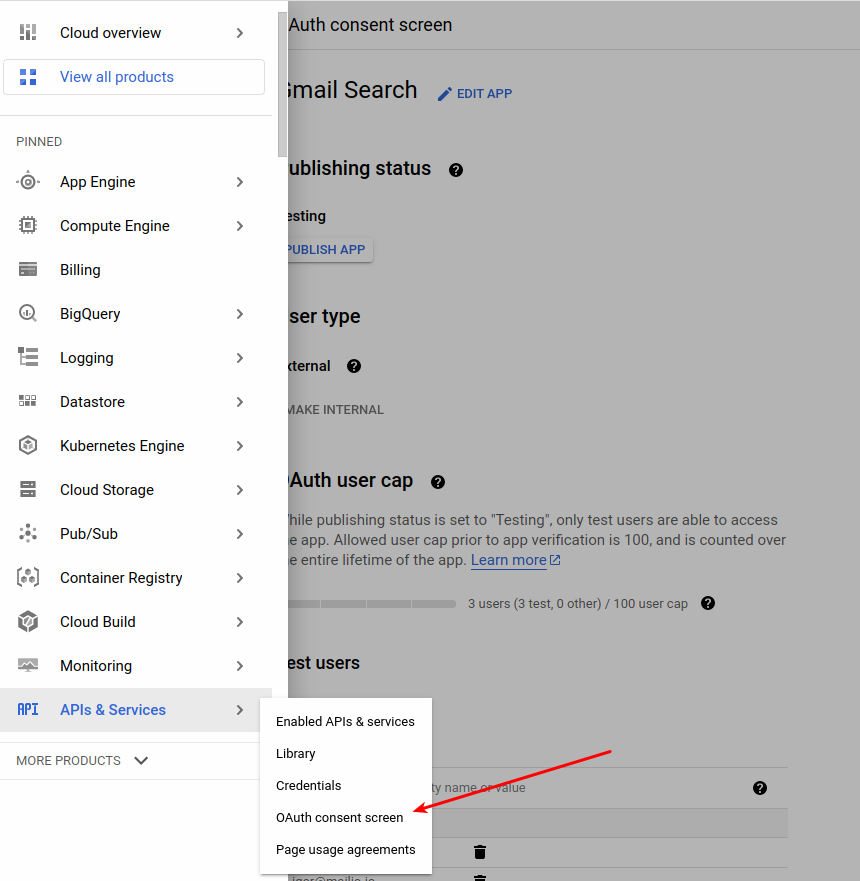
Fill out the consent screen by entering on
Page 1:
- App name (e.g. Gmail Semantic Search)
- User support email
- Developer contact information
Page 2:
Click on Add or remove scopes and add this scope in since we only want to read our emails: https://www.googleapis.com/auth/gmail.readonly
Save and continue.
Page 3:
Add test users. Add your gmail account/s you'd wish to test Semantic search on.
When this is done, navigate to main menu and select Credentials from APIs and Services
Click Create credentials and go to OAuth Client ID.
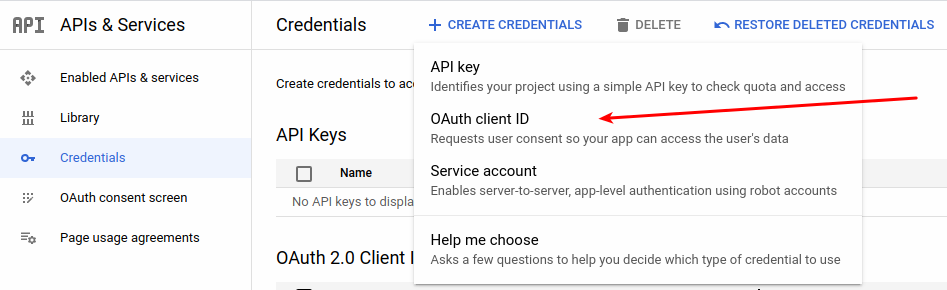
- Choose application type as
Desktop Application - Enter the Application name and click the Create button
- The Client ID will be generated. Download it to your compuster and save it as
credentials.json.
Keep your Client ID and Client Secret confidential.
Python Code Quick Walk-through
Allowing access to our Gmail messages. Here we need to access to formrly created credentials.json in order to be able to authenticate our Gmail account and allow reading our messages.
import os
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from googleapiclient.errors import HttpError
import google.auth.exceptions
from googleapiclient.discovery import build
# If modifying these scopes, delete the file token.json.
SCOPES = ['https://www.googleapis.com/auth/gmail.readonly']
creds = None
# The file token.json stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first
# time.
if os.path.exists('token.json'):
try:
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
creds.refresh(Request())
except google.auth.exceptions.RefreshError as error:
# if refresh token fails, reset creds to none.
creds = None
print(f'An error occurred: {error}')
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
# creds = flow.run_local_server(port=0)
creds = flow.run_console()
# Save the credentials for the next run
with open('token.json', 'w') as token:
token.write(creds.to_json())
Since we're using Colab the above code will request us to follow a link and then paste the validation code back to our program code input.
Please visit this URL to authorize this application: https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=123456.abcdef.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fgmail.readonly&state=woueP4lJfmYWBYbOlfteLpeuNr0Da2&prompt=consent&access_type=offline
Enter the authorization code: Listing and reading our emails using Gmail API. We paginate until approximately CUT_OFF is reached or the end of email messages reached:
emails = [] # indvidiual raw emails stored
CUT_OFF = 10000 # maximum number of emails to be downloaded
try:
service = build("gmail", "v1", credentials=creds)
gmail_messages = service.users().messages()
has_next_token = True
next_token = None
count = 0
while(has_next_token):
results = gmail_messages.list(userId='me', pageToken=next_token).execute()
messages = results["messages"]
if "nextPageToken" in results:
next_token = results["nextPageToken"]
else:
next_token = None
has_next_token = False
size_estimate = results["resultSizeEstimate"]
print(f"next_token {next_token}, size estimate: {size_estimate}")
for msg in messages:
msg_dict = gmail_messages.get(userId='me', id=msg['id'], format='raw').execute()
emails.append(msg_dict)
count += len(emails)
if len(emails) > CUT_OFF:
has_next_token = False
next_token = None
except HttpError as error:
print(f'An error occurred: {error}')Since we're retrieving raw emails we need to parse then. Using BeautifulSoup we strip out all HTML tags and we're left with bare text which we'll use as our sentence corpus (let's call it "email knowledge").
import email
from email import policy
from email.parser import Parser
from io import BytesIO
import io
parser = Parser(policy=policy.default)
# reference content dictionary
content_dictionary = {
}
counter = 0
for email in emails:
msg_str = base64.urlsafe_b64decode(email['raw'].encode('ASCII'))
subject = from_email = to_email = None
msg = parser.parsestr(msg_str.decode('utf-8'))
for key in msg.keys():
if key == "Subject":
subject = msg.get_all("Subject")
if key == "From":
from_email = msg.get_all("From")
if key == "To":
to_email = msg.get_all("To")
print(f"from: {from_email}, subject: {subject}")
for part in msg.walk():
if part.get_content_type() == "text/html":
content = part.get_content()
clear_content = remove_tags(content)
content_dictionary[counter] = {
"id": email["id"],
"subject": subject,
"from": from_email,
"to": to_email,
"body": clear_content,
"snippet": email["snippet"]
}
counter += 1Here the meat of our code. We load a sentence transformer that will create for us "email knowledge" embeddings and later also question embeddings. In this case I'm using all-MiniLM-L6-v2 which is a small model, but it should do the job. You can try replacing this with a bigger model such as all-mpnet-base-v2 and see if there is any improvement in the results.
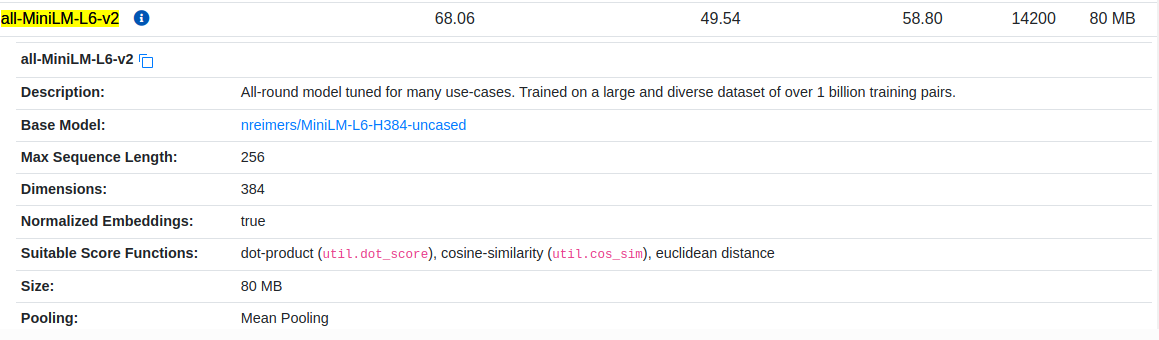
from sentence_transformers import SentenceTransformer, util
import torch
embedder = SentenceTransformer('all-MiniLM-L6-v2')Create email knowledge embeddings which represents our knowledge database in vector format (384 dimensions).
corpus = [c["body"] for c in content_dictionary.values()]
print(f"embedding {len(corpus)} sentences")
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)We also need our queries to use the same "embedder". The query is a simple 384 dimension vector which needs to be matched against our email knowledge database via similarity search.
# Query sentences:
queries = ['how can I learn about machine learning?', 'the latest news in computer vision']The crux of this piece of code is utils.semantic_search which performs a cosine similarity search between a list of query embeddings and a list of corpus embeddings.
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(1, len(corpus))
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)
hits = hits[0] #Get the hits for the first query
for hit in hits:
id = hit['corpus_id']
item = content_dictionary[id]
print(f"query: {query}, subject: {item['subject']}, {item['snippet']} https://mail.google.com/mail/u/2/#all/{item['id']}")Results:
query: how can I learn about machine learning?, subject: ['Recommended: Linear Algebra for Machine Learning and Data Science'], Ready to learn something new? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏͏ ͏ ͏ ͏ ͏ https://mail.google.com/mail/u/2/#all/1872331840302f51
query: how can I learn about machine learning?, subject: ['Intro to Coding Online Course - Applications now open!'], Hi Igor Rendulić, Want to learn how to code? Now's your chance to join Code in Place 2023 – a FREE, 6-week online course that covers the fundamentals of computer programming using the Python https://mail.google.com/mail/u/2/#all/187251157c88c4f7
query: the latest news in computer vision, subject: ['GTC 2023 Day 4: Top Finale Moments 🏁'], Hello Igor, This is Satya Mallick from LearnOpenCV.com. Welcome to Day 4 and the last day of Spring GTC 2023 as we end this season's GTC on a high note 🍾 We have summarized the highlights from Day https://mail.google.com/mail/u/2/#all/18711445e87740e9
query: the latest news in computer vision, subject: ['New Tutorial ✍🏼: Advanced Image Editing using InstructPix2Pix and prompts'], Do you like to see magic? Read on. . . https://mail.google.com/mail/u/2/#all/1872855eebb8e591
Conclusion
The results are surprisingly good even with the `all-MiniLM-L6-v2 model. I haven't run any of the larger models since I don't posses the cash for GPUs on Google Colab (free goes by so fast :) ).
But if I could of done it and get back some nifty relevant results then the future of semantic search is here baby!
It's important not to forget that every answer is very promotional since the email knowledge database is a set of unwanted "spammy" emails.
The full Colab code


Resources
- https://www.sbert.net/examples/applications/semantic-search/README.html
- https://www.sbert.net/docs/pretrained_models.html
A Few more QA examples
Q: where is the best place to buy investment real estate property?
Q: what was the top dividend stock in 2022?
Q: the most healthy lunch
Q: Give me graphic design insipiration
Q: news on Ukraine 2023
Q: what to do when someone hacks your computer?
Q: how much does an iPhone cost?